Friday 2nd March 2018
We are continuing to experience issues with one of our virtualisation farms at this time. Engineers are working on restoring the Hypervisor nodes, which will restore access to servers including some Glide mail stores, web-11 and some DSL / VPN authentication services which are also affected.
On behalf of FidoNet, please accept our apologies for the disruption in service.
1st March, 23:00
Emergency maintenance commences to address security issues in London on our Proxmox cluster. (mitigation for the Meltdown and Spectre security concerns).
1st March, 23:30
The initial patch, applied to a none critical server to test and evaluate the update has managed to impact the cluster replication and communication channel. All cluster nodes have become unresponsive and we are in the process of trying to understand the failure. The nature of the design is such that this should not be possible and simply should not happen.
2nd March, 01:00
Work continues to restore services. We continue to experience problems with the replication system. No data has been lost, however as a precaution we need to remove the file systems and front end nodes from service whilst we work to restore service.
2nd March, 04:00
Recovery is underway however the process is slow. At this time, we believe it may be at least 24 hours before all services are fully restored
2nd March, 06:00
We are continuing to work on the Proxmox server farm. Replication and IGMP services are severly impacted, resulting in a failure of redundancy and migration services. Engineers are working to manually migrate data and customer nodes onto backup servers. The process is extremely slow and time consuming however, and at this stage, we do not envisage having services such as web-11, web-23 and some DSL authentication nodes back online before Saturday morning
2nd March, 12:00
Initial attempts to restore Proxmox cluster services have failed and we are continuing to work to restore the cluster and associated services
2nd March, 14:00
We are close to a solution having identified the main causes and factors associated with the repeated cascade failures. Engineers are continuing to work to restore impacted services as quickly as possible.
2nd March, 17:00
We have now managed to restore the underlying virtualisation platform and associated storage services. Impacted services are now finally starting to return to normal
2nd March, 18:00
We are now confident that all impacted services have been fully restored. We will continue to work with the vendor over the next few days to fully understand the cause of the cascade failure and find ways to mitigate any such issues in the future. Our vendor is in possession of diagnostic data and has already been able to identify and re-create the bug in their test environment and we are expecting a patch in the near future. In the mean time, we have taken steps to mitigate the problem and have been able to restore the HA cluster to full capacity
4th March 2018 – An initial update from our Managing Director
Thank you for contacting FidoNet regarding issues experienced on Friday, and my apologies that it has taken this long to respond to you
As you may be aware, if you were monitoring our live status page https://status.fido.net/ we experienced a number of issues on Friday which took us longer than usual to address and repair
The problems actually began on Wednesday when we started to see an increase in DDoS traffic and it became apparent that there was a new round of attacks under way exploiting the previously known “deluge” attack, exploiting a hole in memcached security (previously this was used to expoit redis)
Our systems worked well and we absorbed/deflated the attacks with relative ease Wednesday and again for most of Thursday, although at one point we were seeing a 900% increase in traffic levels and there was a knock on effect which caused certain services on our Juniper routers to fail silently.
This impacted our Proxmox cluster and resulted in the entire HA cluster failing Thursday evening at approximately 10:37pm. Engineers who were monitoring and deflating the DDoS attack regrouped and started to work on both the continued DDoS and also repairing and restoring the HA cluster. Unfortunately, owning to the nature of the failure, it was several hours before we were able to identify the issue was actually in our Juniper core (igmp/multicast routing daemons failed silently).
Engineers were unable to restore the HA cluster and started to work on manually migrating essential services onto standalone nodes in order to restore some critical services such as DNS cache services and MX receivers. Migrating the volume of data (several TB) took nearly 8 hours, and at the end of this process we were still experiencing strange and unexplained freezes with the Proxmox cluster.
These freezes were eventually traced to a recent security update which had been applied to address the Spectre and Meltdown security issues which you will have already read about in the press.
So, we now had teams working on 3 strands to restore service. By noon on Friday we thought we were there, only to witness an entire cascade failure of the new cluster (due, we believe, to issues with the aforementioned Spectre/Meltdown patches). This however gave our engineers enough information to be able to resolve the similar issue with the main HA cluster. This just left the IGMP routing/proxy issues which were still unexplained. We eventually identified and traced the problem to the Juniper platform and were able to reset the IGMP functions on these routers, which resulted in the HA cluster being restored by 17:15 Friday.
The vendors of our HA cluster solution (Proxmox) have gone away to fix the freeze/process hanging issues which we have identified for them, we are also working with Juniper to fix the IGMP service issues experienced there, and we have also learned several lessons regarding our supposed HA (High Availability) cluster, and the fact we had too many eggs in one basket, even if that basket was carefully designed not to allow the entire service to fail if one (or more) parts experienced issues.
We have also been working on improving our DDoS mitigation techniques and capability in order to ensure that as the severity of the attacks grows, we are still able to deal with and absorb/deflect the bad traffic whilst still allowing the good traffic through.
We are continuing to work on fine tuning services, and are looking at ways of having a better failover in case of another / similar failure in the future. Some customers were impacted because of the failure of the DNS Cache service which resulted in DNS query errors making it look as though their service was down when in fact they were simply unable to contact our DNS accelerators, other customers were impacted by RADIUS login problems when they rebooted their DSL services (because of the DNS lookup problems) and so on.
We did bring up a backup DNS resolver fairly quickly, however it was too late for some customers as they had already rebooted their DSL connections which resulted in them then being unable to authenticate as the authentication servers were offline due to the HA cluster failure, and so on.
We have a number of small changes planned which will address the above short comings. We are also looking at additional training to ensure that we can identify IGMP failure modes more quickly. (For example, had we identified the IGMP issues early enough, we may have been able to restore services prior to 8am Friday morning .. and so on).
Jon Morby
tel: 0203 519 0000
web: www.fido.net
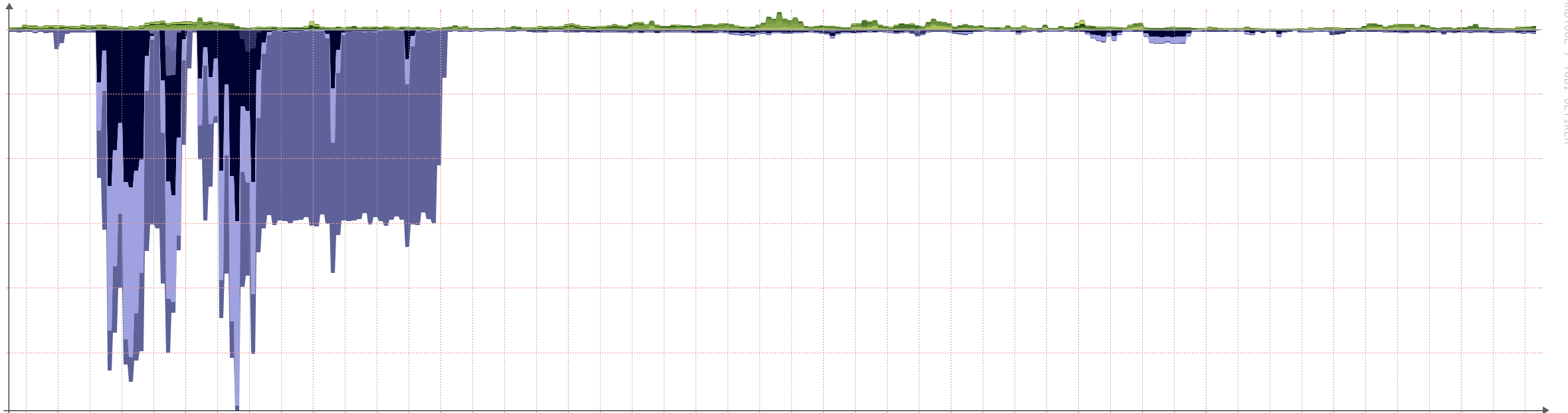
Graphs of the DDoS traffic we had to contend with
Levels in a 6 hour period
Usual levels over a year
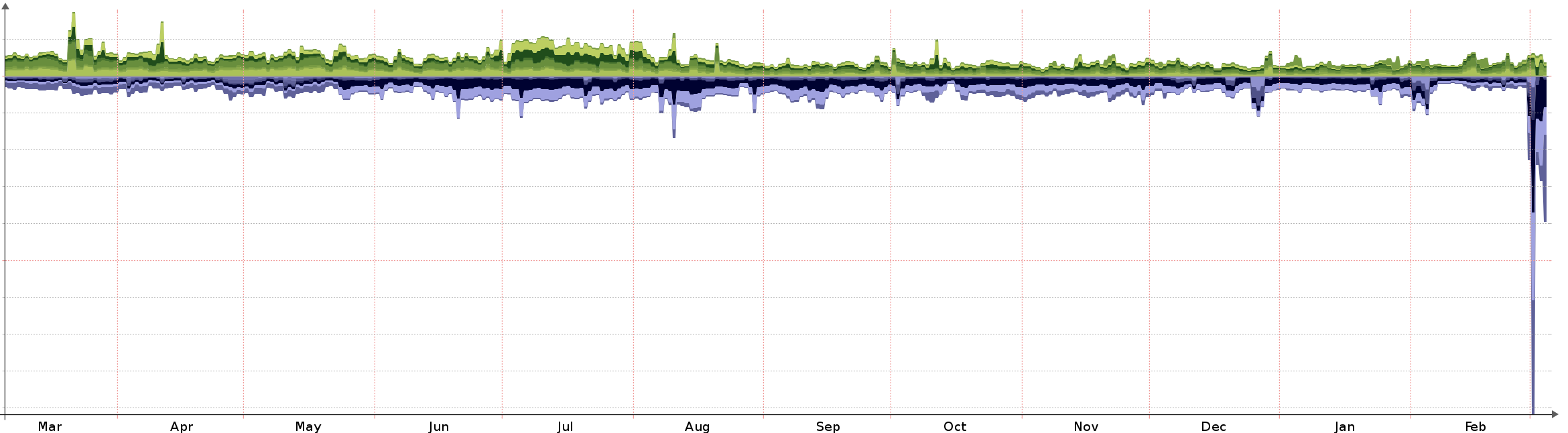
You will note the excessive levels of traffic we saw at our borders when the attacks took place and before we were in a position to mitigate and clean the traffic